Accelerating Seq2Seq LSTM Training - GPU vs CPU
GPUs can be effectively used in parallel for massive distributed computational processes.But GPU usage needs to be tailored to your model architecture.
Introduction
Graphics processing units (GPUs), originally developed for accelerating graphics processing, can dramatically speed up computational processes for deep learning. They are an essential part of a modern artificial intelligence infrastructure, and new GPUs have been developed and optimized specifically for deep learning.
So when recently working on a task that involved using an autoencoder to create embeddings from text data, I thought that using a GPU would be a no brainer. The reality was more complicated.
No performance improvement
The encoder I used for the autoencoder was composed of a Bidirectional LSTM layer with a ReLu activation. But for simplicity’s sake, let’s look at a bare-bones LSTM model.
model = Sequential()
model.add(LSTM(64, activation=ReLU(alpha=0.05), batch_input_shape=(1, timesteps, n_features),
stateful=False, return_sequences = True))
model.add(Dropout(0.2))
model.add(LSTM(32))
model.add(Dropout(0.2))
model.add(Dense(n_features))
model.compile(loss='mean_squared_error', optimizer=Adam(learning_rate = 0.001), metrics='acc')
model.fit(generator, epochs=epochs, verbose=0, shuffle=False)
When running the code I received this log warning, but I was not concerned since I figured the code would still achieve a considerable speed up by utilizing the GPU.
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
My assumption was reinforced by what Nvidia has on their page describing LSTM acceleration:
Accelerating Long Short-Term Memory using GPUs
The parallel processing capabilities of GPUs can accelerate the LSTM training and inference processes. GPUs are the de-facto standard for LSTM usage and deliver a 6x speedup during training and 140x higher throughput during inference when compared to CPU implementations. cuDNN is a GPU-accelerated deep neural network library that supports training of LSTM recurrent neural networks for sequence learning. TensorRT is a deep learning model optimizer and runtime that supports inference of LSTM recurrent neural networks on GPUs. Both cuDNN and TensorRT are part of the NVIDIA Deep Learning SDK.
Source: https://developer.nvidia.com/discover/lstm
Yet I did not notice any speed up during training. When I compared the training times on GPU vs CPU while varying the batch size, I got:
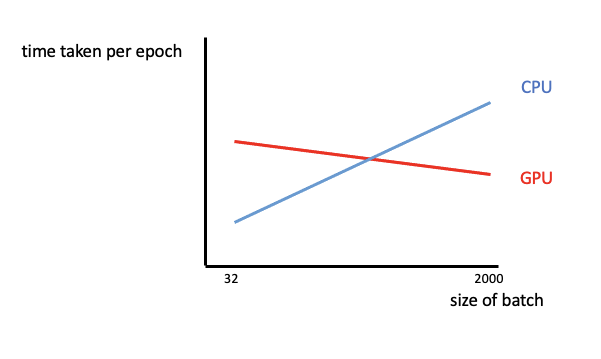
So CPU on small batch sizes perform better than GPUs, which only achieve superior performance as batch size increases dramatically. What could be the reason for this?
Explanation
The explanation is rather simple; while the Bidirectional LSTM architecture is great for working with text data like IMDb reviews, TensorFlow uses an inefficient implementation of the LSTM on the GPU. The reason is probably that recurrent calculations are not parallel calculations, and GPUs are great for parallel processing.
Further, CUDNN has functionality to specifically accelerate LSTM and GRU layers. These GRU/LSTM layers can only be accelerated if they meet a certain criteria. This is what Francois Chollet, creator of keras library, main contributor of tensorflow framework, said about RNN runtime performance in his book Deep Learning with Python 2nd edition:
When using a Keras LSTM or GRU layer on GPU with default keyword arguments, your layer will be leveraging a cuDNN kernel, a highly optimized, low-level, NVIDIA-provided implementation of the underlying algorithm. As usual, cuDNN kernels are a mixed blessing: they’re fast, but inflexible—if you try to do anything not supported by the default kernel, you will suffer a dramatic slow- down, which more or less forces you to stick to what NVIDIA happens to provide. For instance, recurrent dropout isn’t supported by the LSTM and GRU cuDNN kernels, so adding it to your layers forces the runtime to fall back to the regular TensorFlow implementation, which is generally two to five times slower on GPU (even though its computational cost is the same).
To reinforce the point, in his blog post on benchmarking TensorFlow on cloud CPUs, Max Woolf analyzes the performance of Bidirectional LSTMs versus CPUs in terms of training time. His results speak for themselves as to how using a GPU for this architecture won’t give you the performance acceleration you are expecting:
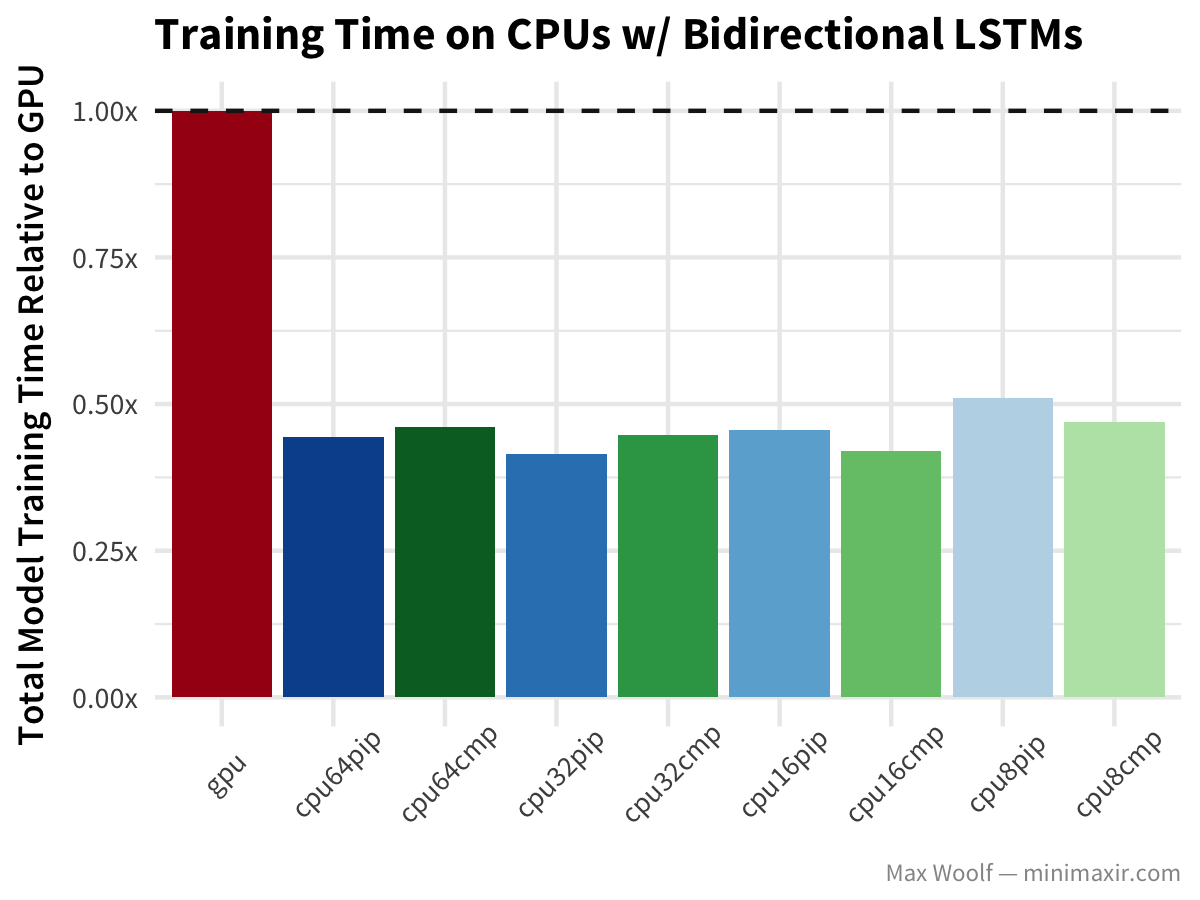
Source: https://minimaxir.com/2017/07/cpu-or-gpu/