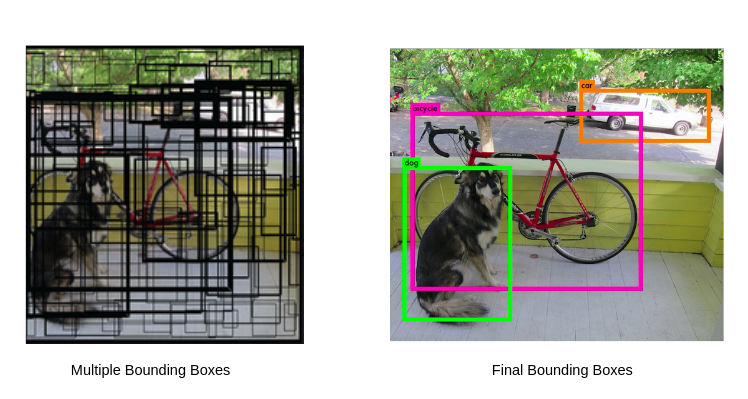
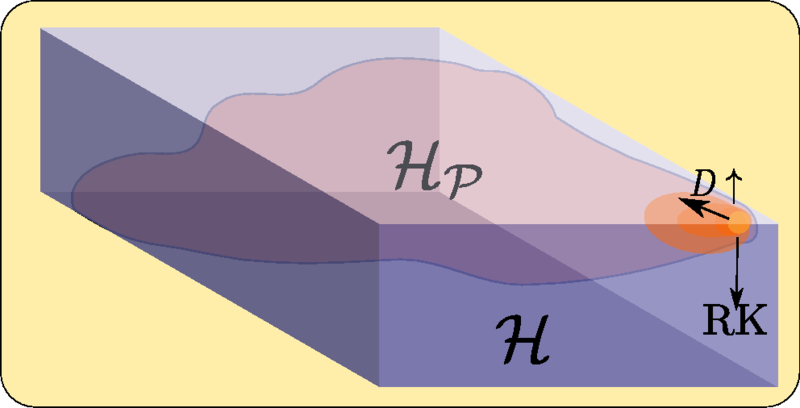
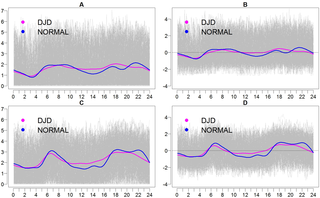
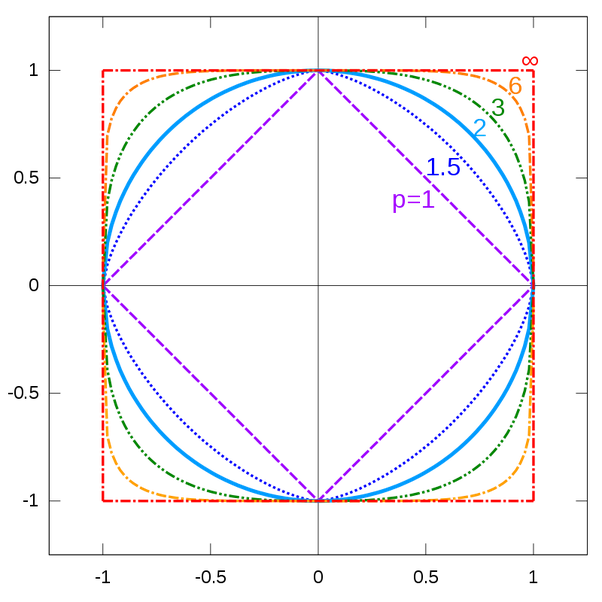
A theoretical discussion of learning theory, specifically the construction of a hypothesis space in ML/DL, and how it can be formulated as a Reproducing Kernel Hilbert Space.
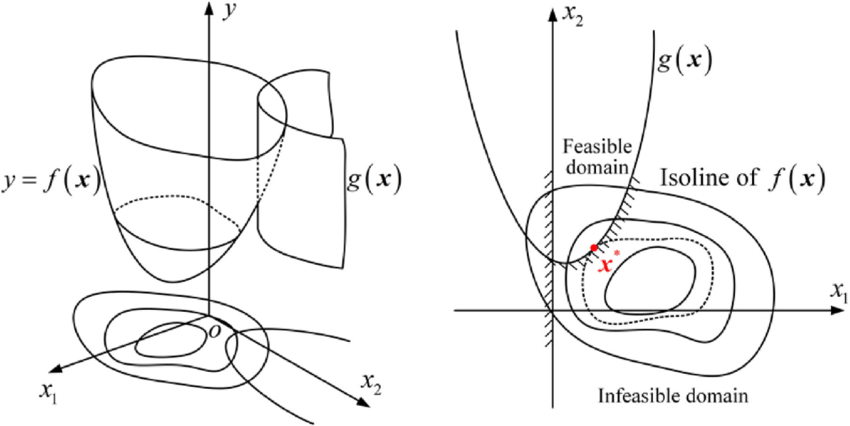
A mathematical overview and practical application of the ADMM optimization algorithm, a useful alternative to Stochastic Gradient Descent (SGD) as a deep learning optimizer.
GPUs can be effectively used in parallel for massive distributed computational processes.But GPU usage needs to be tailored to your model architecture.
Normalizing vectors of log probabilities is a common task in statistical modeling, but it can result in under- or overflow when exponentiating large values. The log-sum-exp trick for resolving this issue.